Python İle Web Scraping: Temeller

Merhaba,
Gün içinde birçok web sitede geziyoruz. Bu mecralardaki fotoğraf, tweet, yazı, fiyat gibi kayıtların aynı zamanda “veri” olduğunun pekala farkındayız. Bu verinin farkı ise bir veritabında, excelde veya csv dosyasında değil de bir web sitede ürün olarak karşımıza çıkıyor olması.
Peki oluyor ya arada, bu sitelerdeki verilere ihtiyacımız olursa ne yapacağız? Kimi web siteler ücretli veya ücretsiz verileri API’lar ile kullanıma açabiliyor, kimisi tabloları indirme bağlantısı paylaşıyor; peki ya bunları sağlamıyorlarsa bu verileri nasıl alabiliriz? Yöntem basit, tek tek bütün satırları kağıt kalem ile kaydedebiliriz veya bir Excel tablosu açıp her gördüğümüz değeri tek tek Excel’e yazabiliriz ama efektif bir yöntem değil bu. Burada imdadımıza Web Scraping yetişiyor, bu yöntemle verileri tek tek kaydetme işlemini otomatize edebiliyoruz. Bu yazı serimizde Web Scraping ve kullanım alanları üzerinde duracağız. Yol haritamız şöyle:
- Web Scraping temelleri,
- E-ticaret sitelerinden otomatize scraping,
- Web Scraping kullanarak Twitter botu oluşturma.
Web Scraping
Web Scraping web sitelerinde sunulan içerikleri programlama dilleri yardımı ile alma yöntemidir. İşlem aslında tek tek siteleri tıklamamız ve gördüklerimizi kağıt kalem ile kaydetmemize eşdeğer bir süreç, sadece programlama dilleri saatler sürebilecek bu süreci saniyeler içerisinde gerçekleştirmemizi sağlıyor. Sitelerden sadece site yöneticilerinin kullanıcılara sundukları bilgileri (html, xml vb. formatta) alıyor olduğumuz için aslında yaptığımızda yanlış bir şey yok. Fakat içeriği kullanım amacınıza göre ilgili site yönetiminden izinler almanız gerekli olabilir. Eğer ki verileri çektiğiniz sitenin kazanç kaynağı ürünlerin fiyatlarını sunmak ise (ürün satmaktan farklı bu bahsettiğim), kullanıcıları bu sitelerdeki verileri görmek ve paylaşmak için ücret ödüyor ise bu sitelerden izinsiz veri çekme işlemleri hukuki yönden sıkıntılar çıkartacaktır.
Bir web sayfasında mouse ile sağ tıklayıp “sayfa kaynağını görüntüle” dediğimizde karşımıza çıkan yazılar, karakterler aslında bizim gördüğümüz web sayfasının bütün detaylarının belirlendiği kısım. Web Scraping işleminde aslında o kısımda yer alan html taglarını ayrıştırarak odaklandığımız verileri aradan çekip çıkarıyoruz.
Web Scraping örneklerimiz için çok çok basit düzeyde html bilgisi gerekiyor. Ben bu sürece “html okumak” diyorum, html’i yazabilmemize gerek yok Web Scraping için basit düzeyde okuyabilmemiz yeterli.
Bu yazı serimizde çok basit düzeyde scraping işlemlerini göreceğiz ve bunun için Python – Beautiful Soup kütüphanesini kullanacağız. Seride kullanacak olduğumuz web sitelerini ise örneklerin nokta atışı ve daha anlaşılır olmasını amacıyla kendi oluşturduğum web sayfaları üzerinden ilerleyeceğiz. Bu yazıda kullanacak olduğumuz web sayfamız: https://bilative.github.io/sisterslab/web_scraping

Uygulama
Öncelikle daha önce kullanmadıysanız import öncesi beautifulsoup ve request paketlerinin pip installation işlemlerini yapmanız gerekecektir. Bu süreçte:
- İlk olarak bir web sitesine get request (istek) atıp bir kez sayfa içeriğini (html olarak) görüntülüyoruz. Bu işlem tarayıcıda sağ tıklayıp “sayfa kaynağını görüntüle” dediğimizde gördüğümüz tüm içeriği almamızı sağlıyor.
- Ve daha sonra bu html kodlarınını -elde etmek istediğimiz bulunduğu alanın bilgilerine göre- filtreleyerek gerekli bilgiyi aradan sıyırıp alıyoruz.
İstek atma ve içeriği alma kısmında “request” paketinden yararlanıyor ve bu html kodlarının düzeltilmesi ve tag’ler olarak ayrıştırılması kısmında da Beautiful Soup paketinden yararlanıyoruz.
Burada bahsettiğimiz gibi sayfa içerisindeki tüm html içeriği soup içerisine kaydedildi.
Tablo Verilerini Kazımak
Tablo verilerini kazımadan önce işimizi kolaylaştıracak bir işlem olarak web sayfasında “sayfa kaynağını görüntüle” işlemini yapıp “Ctrl + F” kombinasyonu ile tablo elemanlarını aramakta fayda var. Bu şekilde direkt kazımak istediğimiz bölümün taglerine ve class bilgilerine ulaşabiliriz. Örnek olarak bu alanda Ctrl + F sonrası “Icimizdeki Seytan” kelimesini arayalım. Direkt olarak gittiğimiz satırda “td” etiketinde “col9” class’ının belirlendiğini görebiliyoruz, ve tüm kitap isimleri “col9” class’ı ile tanımlanmış. Html td etiketi satırları gözelerini belirtir. Buradan aldığımız bilgiler doğrultusunda Beautiful Soup’a arama işlemimizin sınırlarını söyleyebiliyoruz.
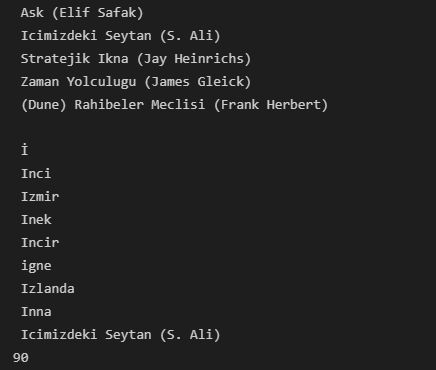
Bu şekilde tablonun tüm elemanlarına ulaşmak, filtrelemek ve bunları dataframe’e çevirmek bize kalmış. Örnek web sayfası üzerindeki daha detaylı örnekleri buradaki github reposundan görüntüleyebilirsiniz.
E-Ticaret Verilerini Kazımak
Ürün hakkında özet bilgileri barındıran ürün kutucuklarını tüm e-ticaret sitelerinde görebiliyoruz. Bu kutulara tıklayınca ürünlerin detaylı sayfasına ulaşabiliyoruz. Web sayfaları gezinirken direkt olarak göremesek de o kutucukta yazan bilgiler ile birlikte ürünün sayfasının linki ve satıcısının profil linki de o kutucuğa gömülü ve hatta oradaki küçük görselin de bilgisi de o kutucukta yer alıyor. Tıklayınca bizi yönlendiriyorsa o bilgi orada bir yerde olmalı, değil mi?
Kaynak kodlarının olduğu kısma geldiğimizde mesela “Bilal Manavcilik” linkine ulaşmak istediğimizi varsayalım. Bunu aradığımızda “a” etiketi içerisinde yer aldığını, bir url barındırdığını ve “urun-satici” div’i içerisinde yer aldığını görüyoruz. O zaman bu şekilde bir filtreleme” işlemi yaparak bu bilgiyi ayrıştırmak da mümkün.
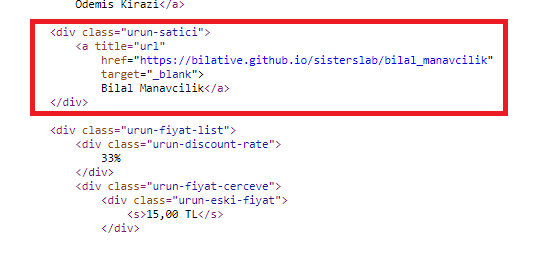
Tüm ürün satıcılarının isimlerine ve profil url’lerine ulaşmak için ise şöyle bir yol izlememiz gerekiyor.
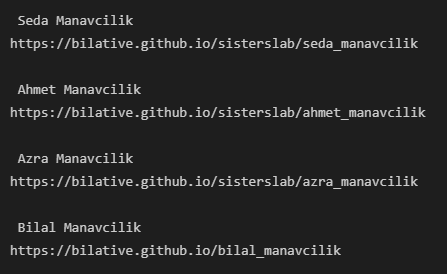
Tabii ki de tekil olarak verileri almak pek bir şey sunmuyor bizlere, ürünlerin bilgileri ile dataframe oluşturma için de şöyle bir yol izleyebiliriz:

Bu yazımızda çok basit düzeyde örnekler ile Python ile Web Scraping konusuna giriş yaptık. Değindiğimiz örnekler Web Scraping konusunda ilerledikçe en fazla kullanma ihtiyacı hissedeceğimiz 2 konuydu. İlk başlarda html bilgisi olmayanlara belki süreç karmaşık görünüyor olabilir fakat adaptasyon çok hızlı olacaktır ve kısa sürede html bilgisi de kazanmayı sağlayacaktır bu uğraş.
Web Scraping gerçekten çok keyifli bir konu olmakla birlikte bazı püf noktalara da dikkat etmek gerekiyor. Serimizin sonraki adımlarında daha da derinleşerek bu alanda farklı kullanım örnekleri sunacağız.
Bir sonraki yazıda görüşmek üzere.

Ben Bilal Latif Ozdemir, DEU İstatistik bölümü mezunuyum ve su an Ege Üniversitesi Bilgi Teknolojileri programında yüksek lisans yapıyorum.
Aynı zamanda su an İzmir'de veri bilimci olarak çalışıyorum. Veri bilimi, Python ve istatistiksel analizler üzerine kendimi geliştirmeyi seviyorum ve bu alanda çalışan kişilere destek olmaya çalışıyorum.