Adım Adım Veri Görselleştirme: Çeşitli Senaryolar ile Görselleştirme

Merhaba, serimizin önceki iki yazısında bir temel atmıştık, bu bölümde bazı sorulara cevap olan görseller sunuyor olacağız. Önceki yazılara göz atmanızı öneririm:
- Adım Adım Veri Görselleştirme: Tipler Ve Tüyolar.
- Adım Adım Veri Görselleştirme: Python Temelleri
Bu yazıda oluşturulan örnek görsellerde hepimizin anlayabileceği, üzerine fikir yürütebileceği bir konu olan vücut ölçülerini barındıran “Body Fat Prediction Dataset“ini kullandım. Kaggle’dan ulaştığım bu veri setini indirip kurcalayabilir, veri hakkında daha detaylı bilgiye sahip olabilirsiniz.
Not: Bu yazıda temel sorular üzerinde gidilip, bazı önemli ön kontrol ve ara aşamalar atlanmaktadır. Temel amaç görselleştirme olup en doğru bilgi için daha detaylı çalışma gerekmektedir.
Öncelikle bazı metrik dönüşümler ve ek hesaplamalar yaptım. Kimi veriler bize biraz uzak IBS ve INC cinsinden metrikler ile ifade ediliyordu, bunları cm ve kg cinsine dönüştürmem gerekti. Bu gibi ara hesaplamalar ve tüm kodlara github adresimden ulaşabilirsiniz.
Şüpheli bir durum olup olmadığını anlamak için değişkenleri box plot ile kontrol edebiliyoruz. Box plotı birden fazla değişken için tek tek oluşturmak veya tek tek değişken bilgilerini girerek eklemeler yapmak mümkün olsa da bir for döngüsü ile tekrardan kaçınarak tek seferde görseli oluşturmak bize kolaylık sağlayacaktır.
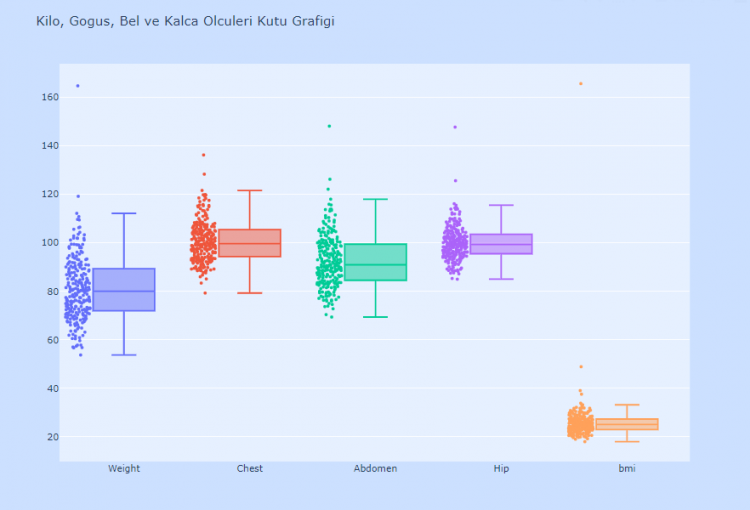
Bu görselde direkt gözümüze BMI değerinin 160’ları bulduğu bir gözlem çarpmış olmalı. BMI değeri normalde 25 civarı olması beklenen, 40 üzerindeyken ciddi tehlikeye işaret eden bir durum. Bu değerin gözlemlendiği kişiye baktığımda bu kişinin 44 yaşında 92kg ve 75cm boyunda olduğunu gördüm. Bir karışıklık olduğu ortada, bir hatalı veri girme durumu olabilir veya bu arkadaşımız engelli olabilir, standart ölçümlerde beklenmedik çıktılar elde edilmiş olabilir.BU nedenle bu gözlemi sonraki aşamalarda dışarıda tutmayı uygun buldum.
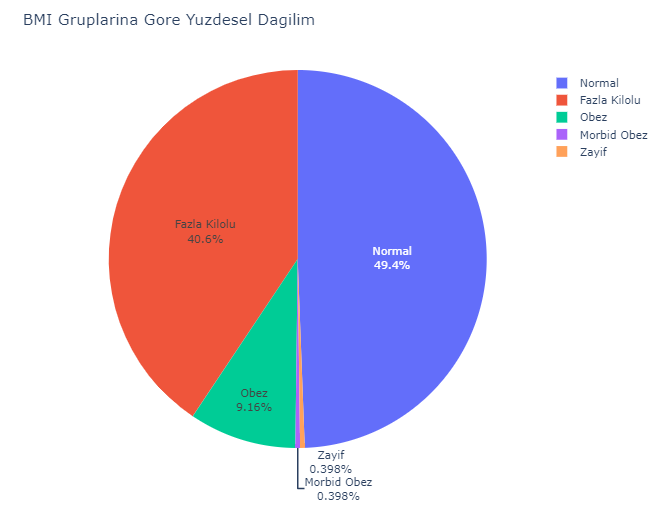
BMI skorlarının düştüğü aralıklar “zayıf”, “normal”, “obez” gibi gruplara işaret ediyor. Bu BMI gruplarının veri seti içerisindeki dağılımı görmek istediğimizi varsayalım. Gösterimimizi Pie Chart ile yapmamız gerekiyor fakat pie chart bir değerin toplamı gibi bir kümülatif gösterim mantığına dayanıyor. Veri setimizde her bir satır 1 kişiyi temsil ediyor olduğundan, her satırın temsil ettiği kişiyi belirtmek için bir dummy değişken oluşturmamız gerekiyor. Bu şekilde pie chart ile ortak dili konuşabiliriz.
Veri setimizde 250 civarı gözlem var. Yaşlar 20-70 aralığında seyrederken hemen hemen her yaştan birden fazla kişi bulunuyor. Biri size şöyle bir soru sorabilir “Aynı yaştaki kişilerin max – min BMI skor farkları nedir?” Mesela 26 yaşında 4 kişi var ise ve BMI skorları sırası ile 20-28-23 ve 19 ise 26 yaşın BMI skor max-min aralığı 28-19=9 olacaktır.
Böyle bir soruda yaşlara göre bir groupby işlemi gerektiği açık olsa da min-range’e ulaşmamızı sağlayan bir aggrigation func bulunmamakta, böyle bir durumda bu fonksiyonu da bizim yazmamız gerekir.
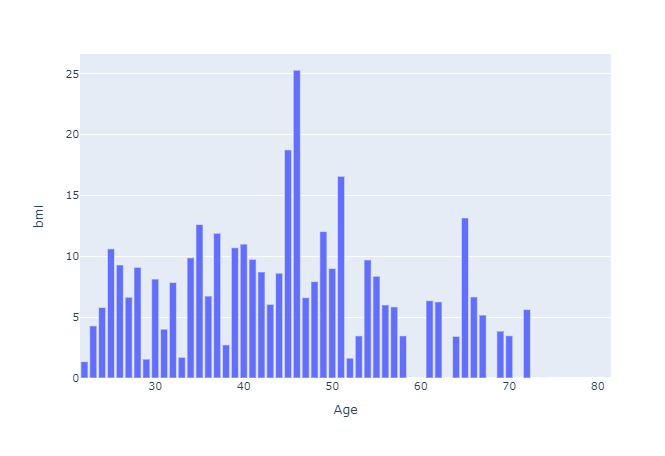
Her bir bar max-min farkını belirtiyorken 0 olan yaşlarda tek gözlem olduğu veya bir gözlem olmadığı, dolayısıyla bir max – min hesabı yapılamadığı sonucuna ulaşılabilir.
Verileri anlama çalışmalarımızın sonu bildiğiniz gibi bir model eğitimine / analizine çıkıyor. Temel olarak regression, classification, time series analysis ve clustering görevlerimiz var. Bir sorudan bağımsız bu veri setine rastgele belirlediğim değişkenleri kullanarak bir clustering algoritması olan KMeans modeli ile kümelenmeleri görselleştirmeye karar verdim.
KMeans ile çok sayıdaki değişkenlerce birbirine benzeyen / ayrılan gözlemlerin aynı veya farklı gruplara düşmesine göre yorumlar yapıyoruz. Burada küme sayısını belirlemek için bir çok yöntem var. Ben bunlardan Elbow Methodu’nu (Dirsek Yöntemi) kullandım. Bu yöntem ile küme sayısı ve hesaplanan WCSS skorları grafiğe döküyor ve büyük dirsek (elbow) kırılmasının olduğu noktadaki küme sayısını optimum küme sayısı kabul ediyoruz. Dirsek noktasındaki hata ne kadar düşükse gözlemler de o kadar güzel / keskin bir şekilde kümelere ayrılabilir yorumu yapabiliriz.
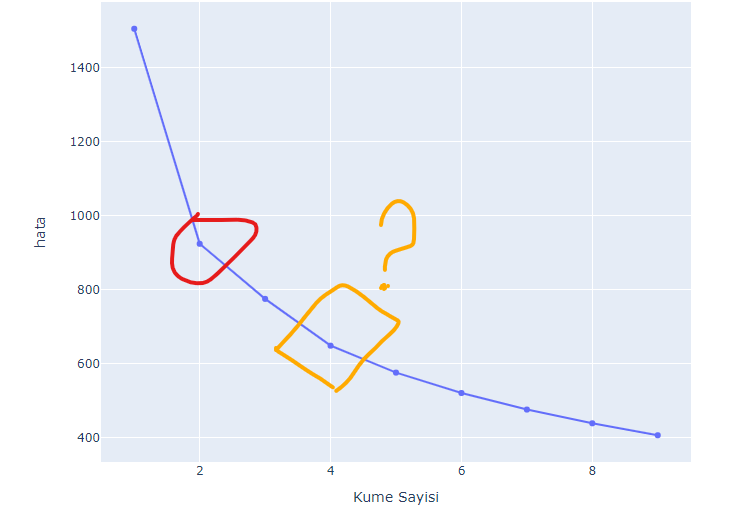
Görsele baktığımızda bir dirsek kırılması göze çarpıyor net olarak. WCSS’nin durağanlaşmayıp giderek azalması grup ayrımlarının keskin olmayacağı konusunda şüpheye düşürebilir bizleri. İlla bir karar vermek gerekirse 2 ve 4 noktalarındaki kırılmalardan durağana daha yakın olan 4 noktasını seçerek devam ediyorum analizime.
Kümeleme sonuçlarını bir görselde göstermek çok da kolay değil aslında. Çünkü eğitimde kullandığımız 10 kadar değişkeni en düzgün gösterim 10 boyutlu bir düzlemde gösterim ile olacaktır. Bu da insan algısının çok üzerinde bir boyut sayısı olduğundan scatter plot ile 2 boyut ile gösterebilmek için bir yardımcıya ihtiyacımız var. 10 boyutlu veriyi 2 boyuta indirgemede de PCA’den yardım alıyoruz. Normal şartlarda PCA’de normal dağılım gibi varsayımlara sahip, fakat temel amacımız görseller hakkında bilgi vermek olduğu için bu kontrolleri yapmıyorum şuan.
PCA yüksek boyutlu veri setinin değişkenliğini biraz bilgi kaybı ile daha düşük boyutlarla temsil edecek dönüşümü sağlayan bir yöntem. 10 boyutlu verimizi böylelikle 2 boyuta indirgiyor ve KMeans sonuçlarımızı PCA ile elde edilen 2 Principle Component ile gösteriyoruz. (Bu arada 2 component ile %80+ açıklama yüzdesine ulaştık.)
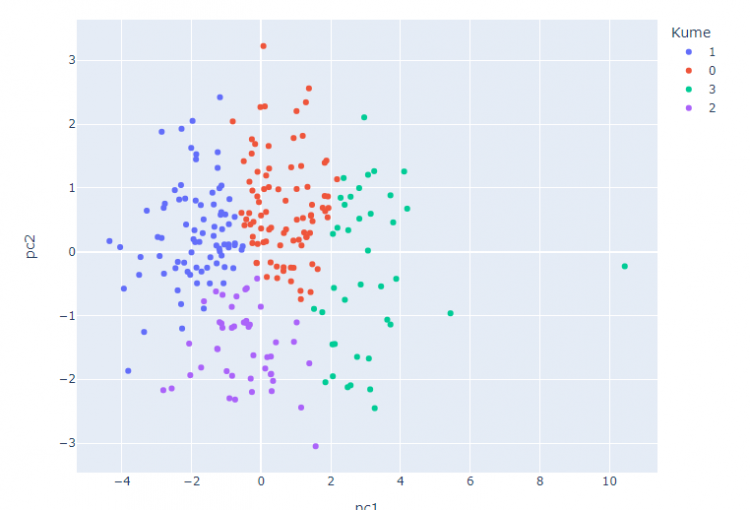
Beklediğimiz gibi kümeler birbirinden keskin bir şekilde ayrılmıyor, fakat 4 kümenin görselini bu şekilde oluşturmuş olduk.
Bu yazımızda bir veri setini görselleştirme teknikleri ile tanımaya ve bazı sorulara cevap bulmaya çalıştık. Ek olarak bir kümeleme algoritmasında görselleştirme teknikleri nasıl efektif bir şekilde kullanılır bunlara değindik.
Bir sonraki yazımızda yine Python ile dinamik bir dashboard olşturduğumuz bir web app yapacağız.
Veri analizi ve veri manipülasyonu hakkında herhangi bir sorunuz ile ilgili iletişime geçmekten çekinmeyin. Serinin sonraki yazısında görüşmek üzere.

Ben Bilal Latif Ozdemir, DEU İstatistik bölümü mezunuyum ve su an Ege Üniversitesi Bilgi Teknolojileri programında yüksek lisans yapıyorum.
Aynı zamanda su an İzmir'de veri bilimci olarak çalışıyorum. Veri bilimi, Python ve istatistiksel analizler üzerine kendimi geliştirmeyi seviyorum ve bu alanda çalışan kişilere destek olmaya çalışıyorum.